




Avant-propos▲
CVS (Concurrent Versions System) est un outil d'aide au développement de logiciels. Très présent dans le monde des programmeurs Open Source, il est utile à la communauté des développeurs pour plusieurs raisons.
Tout d'abord, comme cela transparaît dans son nom, CVS permet une gestion efficace et riche des différentes versions pour un projet logiciel. Cela passe notamment par la mise en place d'un suivi, et par conséquent d'un historique, pour l'ensemble des fichiers appartenant au projet.
Il est également à noter que la gestion de versions se fait autant au niveau de l'ensemble du projet qu'au niveau de chaque fichier pris séparément.
L'un des autres points forts de CVS est de permettre et de favoriser un développement en équipe. En effet, il permet un stockage centralisé du code source sur un serveur et gère les accès concurrents sur les fichiers de développement. Ce qui distingue CVS d'autres outils de développement collaboratif (notamment RCS) est la possibilité pour les développeurs d'accéder en même temps à un même fichier pour le modifier, avec une prise en charge des modifications lorsque celles-ci ne génèrent pas de conflits.
Enfin, comme tout outil de gestion de configuration, CVS s'intègre au processus qualité et permet non seulement d'introduire des règles pour une équipe, mais également de conserver un historique complet de ce qui a été fait.
Cet article a pour but de présenter les grands principes de CVS et d'introduire les possibilités offertes dans le cadre d'un développement seul ou en équipe. Étant donné que mon premier contact avec CVS lors de mes études s'est fait dans le cadre d'un projet réalisé sous Windows (le serveur était CVSNT), j'ai essayé de rester assez général dans mon propos pour éviter de rentrer dans toute la partie configuration qu'on pourra avoir dans un environnement Unix. Concernant les parties spécifiques à un système d'exploitation, il en sera fait mention de façon explicite le cas échéant.
Bien entendu, toute remarque constructive est la bienvenue (idées d'approfondissement, améliorations…). Merci de privilégier les forums pour vos questions sur le sujet.
Remerciements▲
Je tiens avant tout à remercier Greybird pour m'avoir mis sur la piste de cet article, pour sa relecture, ses conseils, et ses explications pour la publication, mais également Laurent Dardenne pour ses suggestions.
Mes remerciements vont également droit vers les membres de Developpez.com qui œuvrent pour un processus de publication d'une qualité remarquable.
I. Généralités▲
CVS fonctionne principalement en mode client/serveur (depuis la version 1.5) : les données sont centralisées sur le serveur et ordonnées en modules, et les développeurs peuvent extraire un ou plusieurs modules sur leur poste local pour faire des modifications et demander au serveur de prendre en compte ces modifications en définissant de nouvelles versions pour les fichiers modifiés.
On dénombre cinq méthodes d'accès :
- l'accès direct ;
- l'accès en mode serveur (pserver) ;
- l'accès en mode serveur GSSAPI (gserver) ;
- l'accès en mode serveur kerberos (kserver) ;
- l'accès en mode rsh/ssh (ext).
À noter que les deux dernières méthodes sont recommandées du point de vue sécurité. Ces modes proposent notamment le cryptage des informations qui transitent sur le réseau.
CVS est également de plus en plus utilisé sur Internet et il est possible d'en utiliser directement les fonctionnalités (pas d'opérations d'écritures néanmoins) sur les sites sans avoir à installer quoi que ce soit sur son poste.
I-A. Vocabulaire▲
Voici quelques points de vocabulaire pour la bonne compréhension de la suite de cet article :
- une révision : employé pour caractériser une version d'un fichier seul ;
- une version : plutôt employé pour parler d'une version du projet/module ou d'une version logicielle ;
- repository : nom donné au répertoire d'accueil au niveau du serveur CVS ;
- module : nom caractérisant un projet/sous-projet disponible sur le serveur CVS.
I-B. Gestion de révisions▲
À chaque modification d'un fichier, répercutée au niveau du serveur CVS, une nouvelle révision du fichier est créée sur le serveur. Néanmoins, les révisions précédentes ne sont pas perdues, le développeur peut à tout moment demander une ancienne révision d'un fichier au serveur.
I-C. Stockage des informations▲
On pourrait se demander quelle est la valeur ajoutée d'un outil comme CVS qui à première vue ne fait qu'automatiser des traitements pour gérer une multitude de fichiers avec pour chacun d'eux un ensemble de révisions.
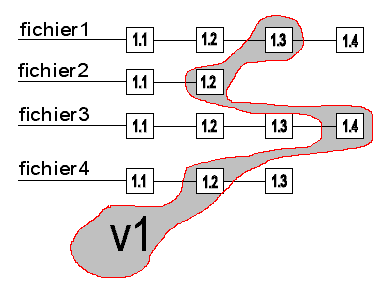
Un premier élément de réponse se situe au niveau de la méthode de stockage de CVS héritée de son prédécesseur RCS (Revision Control System) : avec une méthode de gestion des révisions originale, CVS peut se vanter de pouvoir réduire les coûts de stockage. En effet, le principe utilisé n'est pas de sauvegarder chaque révision dans un fichier particulier, mais plutôt d'utiliser un unique fichier correspondant à la révision la plus récente, dans lequel sont précisées les opérations textuelles (l'unité d'écriture visée étant la ligne) nécessaires à l'obtention du code source correspondant aux révisions antérieures.
La liste des modifications pour obtenir une révision donnée est ainsi toujours à considérer par rapport à la révision suivante, et seul est donné le code pour la révision la plus récente.
Par exemple, en éditant un tel fichier, on identifiera assez clairement les informations et la portion de code relatives à la révision en cours, et un peu plus loin on distinguera les informations (commentaires, auteur…) pour la révision précédente, avec toute une codification pour indiquer les modifications à faire à partir de la révision courante. Cette écriture permet de ne faire que très peu de changements lors de la création d'une nouvelle révision. En effet, seule la précédente révision doit être définie par rapport à la nouvelle, toutes les autres révisions étant à chaque fois définies par rapport à celle la suivant immédiatement (la 1.1 se réfère à la 1.2, la 1.2 à la 1.3, et ainsi de suite).
De façon schématique, pour obtenir le code de la révision 1.1 à partir de la révision courante (1.3), il va falloir appliquer la série de modifications définissant le passage de la 1.3 à la 1.2, puis celle définissant le passage de la 1.2 à la 1.1.
Pour illustrer ceci, voici un exemple de fichier au format RCS géré par CVS (le nom original dans le dépôt CVS est test.java,v).
La facilité de mise à jour de ce fichier après création d'une nouvelle révision est illustrée par la présence du fichier après création de la révision 1.2 et après la création de la révision 1.3. Vous n'avez plus qu'à les comparer pour constater la simplicité de mise à jour (je ne parle évidemment pas de la syntaxe utilisée).
I-D. Cas particulier des fichiers binaires▲
Le stockage des informations et la technique utilisée pour obtenir les différentes révisions d'un fichier se prêtent vraiment bien aux fichiers texte, mais ne sont pas du tout utiles pour d'autres fichiers comme des images ou autres fichiers binaires.
Pour traiter des fichiers comme des binaires, il faut le préciser au serveur (soit en précisant une option de commande, soit en configurant le serveur). Dans le cas contraire, on risquera de se retrouver face à des comportements inattendus ayant pour conséquences des pertes de données.
I-E. Architecture▲
Un serveur CVS gère donc des modules (assimilables à des projets). Chaque module correspond à un répertoire du nom de ce module (l'inverse n'étant pas vrai), et l'ensemble de ces répertoires se trouve dans un répertoire de base qu'on appelle le « Repository ». Bien entendu, il peut y avoir plusieurs Repository sur un serveur CVS, et ils seront tous indépendants les uns des autres (un Repository par projet logiciel ou par service par exemple). Les modules permettent de tenir compte de la segmentation d'un projet logiciel en plusieurs projets (ou suivant plusieurs domaines : base de données, objets métiers…) plus ou moins indépendants et de gérer également les autorisations d'accès aux utilisateurs module par module (ce qui peut se paramétrer très facilement en environnement Unix).
À la base du Repository, on distingue donc les répertoires correspondant aux différents modules créés, ainsi qu'un répertoire « CVSROOT ». Dans ce dernier répertoire, on retrouve les fichiers de configuration du Repository, lesquels permettent de gérer les différents services que peut fournir le serveur CVS. Ces paramètres sont donc propres au Repository qui les contient, et permettent par exemple de gérer des alias de modules, des traitements automatiques à intégrer (envoi de mail lors d'une mise à jour) ou encore des traitements spécifiques selon le type de fichiers ajoutés ou mis à jour.
Tous les fichiers de configurations disponibles pour CVS ne sont pas par défaut dans le Repository. Ils peuvent bien évidemment être rajoutés « à la main » tout comme n'importe quel script écrit par vos propres soins, voire un exécutable pour les utilisateurs avancés.
La création d'une base CVS (c'est-à-dire une structure reposant sur un Repository) se fait à l'aide d'assistants (par exemple avec cvsnt) ou par l'intermédiaire de la commande cvs init (après s'être placé dans le répertoire d'accueil au niveau du serveur).
Pour un serveur sous Windows, il est nécessaire de passer par cvsnt pour définir le chemin vers la base CVS sur la machine serveur ainsi que le raccourci (alias) permettant d'y accéder (par exemple /cvs).
La particularité de ces fichiers de configuration réside dans le fait que la majorité d'entre eux peuvent (et il est plutôt conseillé de faire ainsi) être modifiés en utilisant le principe de CVS, c'est-à-dire en créant de nouvelles révisions. Ils peuvent ainsi être gérés de la même manière que les fichiers du projet de l'équipe de développeurs et on peut très facilement revenir en arrière dans une configuration.
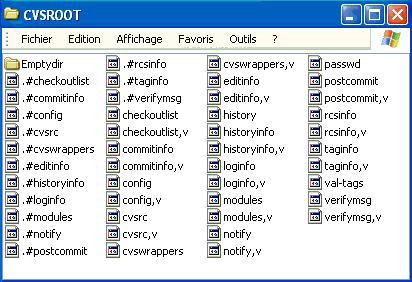
Voici quelques éléments permettant de comprendre la répartition des fichiers dans le répertoire correspondant à un module.
Ce répertoire contient trois types d'informations :
- un répertoire caché appelé « CVS », lequel contient une série d'informations sur le module ;
- un fichier du nom de « .owner » qui contient le nom de l'utilisateur ayant créé le module ;
- l'ensemble des fichiers (avec éventuellement des sous-répertoires) qui correspondent au code source stocké sur le serveur. Les noms des fichiers sont presque les mêmes que ceux utilisés par les développeurs, seul « ,v » a été ajouté à la fin (par exemple, le fichier « User.java » apparaîtra sous la forme « User.java,v »). Cette notation est héritée de RCS.
Si on continue d'explorer les répertoires, on peut noter la présence du fichier « .owner » dans chaque sous-répertoire du répertoire de base du module, ainsi que celle du fichier « .perms » qui définit à chaque fois des permissions de lecture/écriture.
Pour être complet, maintenant que la présentation des noms de fichiers côté serveur a été faite, vous pourrez identifier les fichiers dans CVSROOT qui pourront être modifiés en utilisant un client CVS (c'est-à-dire ceux qui se terminent par « ,v »).
II. Utilisation de CVS▲
L'utilisation de CVS se fait habituellement dans un environnement de type Unix. On trouvera donc facilement des ressources pour l'installation et le paramétrage du serveur. Du côté de Windows, l'interface graphique de CVSNT permet de procéder à quelques réglages et lancer les services. Dans ce qui suit, je m'attache à mentionner les aspects selon moi les plus importants de la configuration d'un serveur et de l'utilisation de CVS.
Tout ce qui suit a été testé à partir de CVSNT sous environnement Windows.
II-A. Configuration minimale côté serveur▲
Quel que soit l'outil serveur utilisé, la configuration de base côté serveur est très minimale. En effet, une fois l'accès possible à partir d'un client, l'administrateur pourra paramétrer chaque Repository en définissant de nouvelles révisions pour les fichiers de configuration.
Il s'agit donc de définir un Repository et son implantation sur le serveur. Le logiciel devrait alors créer le répertoire correspondant et initialiser les fichiers de configuration. Dans le même temps, il aura permis de définir un alias pour le Repository : par exemple « /test » pour « C:\CVS\Test » sous Windows, ou encore « /usr/local/cvs » (ou tout simplement un lien symbolique nommé « /cvs ») pour un environnement Unix.
À partir de là (la fiabilité de la configuration par défaut étant dépendante du serveur utilisé), il ne devrait plus rester qu'à configurer les utilisateurs.
Néanmoins, si le Repository s'avère vide, on pourra se placer dans le répertoire et appeler la commande cvs init (notamment pour ceux qui ne travaillent pas sous Windows).
Cette commande crée le module CVSROOT qui contient les fichiers d'administration et de configuration générale de la nouvelle base. Les fichiers de configuration créés sont les suivants :
- checkoutlist ;
- commitinfo ;
- config ;
- cvswrappers ;
- editinfo ;
- history ;
- loginfo ;
- modules ;
- notify ;
- rcsinfo ;
- taginfo ;
- verifymsg.
Les utilisateurs sont définis dans le fichier « CVSROOT/passw » sous la forme suivante :
NomUtilisateur:MotDePasseCrypte:NomUtilisateurSystemCVS étant à la base utilisé sous Unix, il se sert également du fichier de définition des utilisateurs sur la machine serveur (dans le cas d'un Unix/Linux). Ainsi, sans qu'une entrée soit présente dans le fichier « passwd », tout utilisateur Unix défini sur le serveur pourra se connecter à l'aide de ses identifiants sur la machine. J'ai pu vérifier que cela fonctionnait également pour un serveur sous Windows XP (mais il faut nécessairement que l'utilisateur possède un mot de passe !).
Néanmoins, cela peut également se faire par l'intermédiaire du fichier cité précédemment : la seule restriction est d'utiliser pour le paramètre NomUtilisateurSystem le nom d'un compte effectif sur la machine serveur. Cela permet par exemple de définir plus facilement des groupes d'utilisateurs et de gérer les droits par groupes (ce qui ne veut pas dire que la gestion des utilisateurs sous Unix, voire certaines versions de Windows, ne le permet pas).
Le principal problème lors de la création du premier utilisateur vient du fait de pouvoir définir un mot de passe. Il y a plusieurs solutions que l'on peut énumérer :
- éditer le fichier et y mettre la ligne Administrateur::Administrateur, où Administrateur correspond à un compte qui possède tous les droits sur la structure de répertoire CVS. Puis, se connecter (mot de passe vide) et modifier son mot de passe ;
- se connecter directement au serveur à partir de la machine hôte, et créer un utilisateur en mode commande ;
- se limiter aux comptes utilisateur définis sur la machine.
II-B. La connexion▲
Nous avons entrevu, dans la configuration du serveur, l'accès au serveur CVS directement à partir de l'ordinateur sur lequel est installé le serveur. Dans le cadre d'un développement en équipe, nous n'allons naturellement pas utiliser ce genre d'accès.
Ce qui suit se rapportera donc au protocole de connexion pserver qui peut être utilisé (il est certes de moins en moins utilisé au profit de ssh , mais il reste suffisant lorsque l'encryptage n'est pas nécessaire). Mais avant de chercher à se connecter, il convient de positionner une variable d'environnement : en l'occurrence il s'agit de CVSROOT qui décrit la cible (elle contient non seulement l'hôte cible et le Repository cible sur cet hôte, mais également le protocole utilisé pour la connexion).
Pserver est un protocole réseau qui permet de se connecter à un serveur avec identification sécurisée par mot de passe.
Si nous utilisons ce protocole, un exemple de valeur pour la variable CVSROOT est le suivant :
:pserver:Administrateur@172.30.72.11:/testLes différents paramètres qu'on peut identifier sont, après le protocole, dans l'ordre, le nom d'utilisateur (Administrateur), l'adresse IP du serveur (172.30.72.11), et l'alias du Repository (/test). Par la suite, on pourra se connecter au serveur à l'aide de la commande cvs login.
Positionnement de la variable d'environnement sous Windows :
set cvsroot=:pserver:Administrateur@172.30.72.11:/testPositionnement de la variable d'environnement sous Unix (2 possibilités suivant le shell) :
export CVSROOT=:pserver:Administrateur@172.30.72.11:/testsetenv CVSROOT :pserver:Administrateur@172.30.72.11:/testBien évidemment, la connexion peut se faire en une étape, en utilisant une option des commandes cvs :
cvs -d :pserver:Administrateur@172.30.72.11:/test loginPour se déconnecter, il suffira d'utiliser la commande cvs logout .
Pour être complet sur la connexion au serveur, il faut remarquer qu'une fois qu'on s'est connecté, il n'est plus la peine de saisir son mot de passe à chaque commande. En fait, les informations d'identification sont stockées (sous environnement Unix) dans un fichier « .cvspass » du côté du client (dans le répertoire Home), lequel est consulté à chaque commande. En ce qui concerne Windows, ce fichier apparaîtrait dans le répertoire défini par la variable d'environnement HOME…
II-C. Les commandes de base▲
Ce qui suit a pour but d'introduire les commandes régulièrement utilisées permettant de travailler avec un serveur CVS. Le but n'est pas de lister l'ensemble des déclinaisons de ces commandes, mais d'expliquer les actions qui en résultent. Le système CVS repose sur un unique exécutable (le programme cvs) et ce sont donc des sous-commandes que l'utilisateur emploie.
Ces commandes correspondent bien entendu à une utilisation en mode console, et leur description permettra à ceux qui utilisent des outils CVS dans un environnement de développement de mieux comprendre la succession de commandes générées.
La forme générale d'une sous-commande cvs est la suivante :
cvs [<options>...] <sous-commande> [<options sous-commande>...] [<noms fichiers>...]La liste des sous-commandes s'obtient par cvs --help-commands et celle des options de la commande cvs s'obtient par cvs --help-options.
En utilisant ces commandes vous trouveriez comment lister les options spécifiques d'une sous-commande, à savoir cvs -H souscommande.
Les commandes de base pour la communication avec le serveur et le transfert de fichiers sont :
- cvs add
- cvs checkout (ou ses synonymes cvs co et cvs get)
- cvs commit (ou ses synonymes cvs ci et cvs com)
- cvs update (ou ses synonymes cvs up et cvs upd)
II-C-1. Cvs add▲
Cette commande est nécessaire lorsqu'on crée un nouveau fichier et qu'on souhaite l'ajouter au module. Après exécution, seules des modifications sur le poste local auront été faites : il faudra encore mettre à jour le serveur en utilisant la commande cvs commit.
II-C-2. Cvs checkout▲
Un checkout permet de demander au serveur de renvoyer les fichiers d'un module. Ainsi, la commande cvs checkout monmodule va extraire dans le répertoire courant des fichiers obtenus à partir du répertoire monmodule et ces fichiers seront prêts à être modifiés.
II-C-3. Cvs commit▲
La commande commit demande au serveur de valider et d'intégrer les changements qui ont pu être faits sur les fichiers en local. Le serveur mettra donc à jour les fichiers modifiés et leur attribuera un nouveau numéro de révision. Le commit peut se faire sur l'ensemble des fichiers modifiés, ou sur un fichier précis.
II-C-4. Cvs update▲
La commande update a pour effet de mettre à jour les fichiers locaux à partir de versions situées sur le serveur, ou de consulter le statut des fichiers locaux par rapport à ceux sur le serveur.
Cette commande est un peu plus complexe que les précédentes.
Un simple cvs update va lister l'ensemble des fichiers et préciser le statut de ces fichiers dans le serveur par rapport à ceux présents sur le poste local. Mais ce n'est pas tout, l'ensemble des fichiers pour lesquels une nouvelle révision sera disponible sur le serveur seront directement mis à jour sur le poste local.
Ainsi, si vous avez entamé des modifications à partir d'une révision et que quelqu'un a créé une nouvelle révision entre temps, l'appel de cvs update vous permettra de mettre à jour votre copie locale en intégrant les changements induits par la nouvelle révision (ce qui n'exclue pas la possibilité d'avoir à résoudre des conflits). Vos modifications sont alors intégrées en local à la révision la plus récente, vous pouvez tranquillement mettre à jour le fichier sur le serveur avec un cvs commit.
II-C-5. L'importation et l'exportation de projets▲
Il peut arriver de commencer un projet sans outil CVS, puis, pour une raison ou une autre, de devoir transférer l'état actuel du projet sur un serveur CVS pour poursuivre le développement avec cet outil. Pour ce faire, l'utilisateur aura recours à la commande cvs import .
Exemple : dans le répertoire contenant le projet
cvs import -m "mon message" nom_module vendor_tag release_tagCette commande va avoir pour effet de copier vers le serveur l'ensemble des fichiers et répertoires contenus dans le répertoire courant. Il est bien entendu possible de paramétrer l'import afin de ne pas considérer certains fichiers ou de mettre à jour un projet avec de nouveaux fichiers (cas d'un module fourni par une autre entreprise). Les informations vendor_tag et release_tag identifient respectivement l'auteur du dépôt ainsi qu'une information sur la version du projet importé.
L'exportation du projet à partir du serveur CVS est par contre incontournable et permet par exemple d'extraire une version commerciale du logiciel. En effet, la commande cvs export est très proche de la commande cvs checkout et s'en distingue en ne renvoyant pas d'informations internes propres à CVS (cf. le répertoire CVS créé en local). Cette copie n'est donc pas destinée à être modifiée.
cvs export -r Release-2 monmoduleCette commande va ainsi extraire dans le répertoire courant tous les fichiers et la structure de répertoire du module monmodule pour la version identifiée par le Tag (notion sur laquelle nous allons revenir) Release-2.
II-C-6. D'autres commandes utiles▲
La commande cvs status [file] permet de consulter les informations relatives à un ou plusieurs fichiers. Ces informations tiennent compte de l'état des fichiers au niveau local et au niveau du serveur. Elles peuvent ainsi mettre en évidence une édition concurrente de fichiers (dans le cas où quelqu'un valide des modifications pendant qu'on est soi même en train de travailler sur le même fichier).
La commande cvs tag Nom_Tag [file1 file2 …] permet d'affecter un Tag (marqueur) à un ensemble de fichiers (permet justement de ne pas avoir à connaître les révisions qu'il faut demander pour chaque fichier afin d'avoir un ensemble fonctionnel) ou tout un module, afin de définir une version pour le projet.
La commande cvs ls permet de lister côté serveur la structure de répertoire (on pourra lister les sous-répertoires en appelant cvs ls nom_repertoire).
III. Liens▲
- Livre O'Reilly: CVS - précis & concis : https://linux.developpez.com/livres/#L2
- Le site de CVS : http://www.cvshome.org/
- Documentation CVS en anglais : http://ximbiot.com/cvs/manual/
- Un manuel en anglais sur CVS : http://sunland.gsfc.nasa.gov/info/cvs/
- Le site de CVSNT : http://www.cvsnt.org/wiki/
- Un client CVS pouvant être directement utilisé dans l'explorateur : http://www.tortoisecvs.org/
- Un client graphique sous Windows : http://www.wincvs.org/
- Un client graphique écrit en Java : http://www.jcvs.org/
- Un client graphique écrit en Tcl/Tck : http://www.twobarleycorns.net/tkcvs.html
- Le projet CVSweb pour un accès en consultation à un serveur grâce à son navigateur : http://www.freebsd.org/projects/cvsweb.html
- Un nouvel outil de gestion de versions dans la suite logique de CVS : http://subversion.tigris.org/